
新闻中心


我司邹月娴教授课题组在目标语音分离任务方面取得重要研究进展
 发布时间:2020-05-27
发布时间:2020-05-27
 浏览次数:
浏览次数:
近日,我司邹月娴教授课题组在信号处理方向顶级期刊IEEE Journal of Selected Topics in Signal Processing (JSTSP) “基于深度学习的多模态智能”专刊上发表了题为“Multi-channel Multi-modal Target Speech Separation”的学术论文。
目标语音分离任务是指从多人同时说话的混合语音信号中分离出目标说话人的语音,又被称为“鸡尾酒会”问题,该问题于1953年提出,迄今尚未获得圆满解决。作为语音识别的前端技术,语音分离一直是机器听觉中自然人机交互中的关键技术之一,长期以来受到学界和业界的高度重视。目前的语音分离方法在嘈杂、混响条件下性能急剧下降,难以满足实际语音识别技术的需求。
借鉴人类的听觉机制,该论文探索如何利用视觉-听觉(visual-audio)信息提升远场环境下的目标语音分离性能,提出一种通用的多模态目标语音分离框架。该框架利用目标说话人所有的可用信息,包括他/她的空间位置、嗓音特征和唇部运动,来分离目标说话人语音。在该框架下,该论文研究了多种多模态融合及建模方法,启发于语音识别领域因子分解层在快速环境适配中的进展,提出一种基于因子注意力的音视频融合方法,以聚合多模态高层语义信息。该方法通过将混合语音特征映射到多个声学信息子空间,利用来自其视觉模态的目标语音关联信息和基于可学习注意力机制对声学子空间信息进行有效选择和聚合。
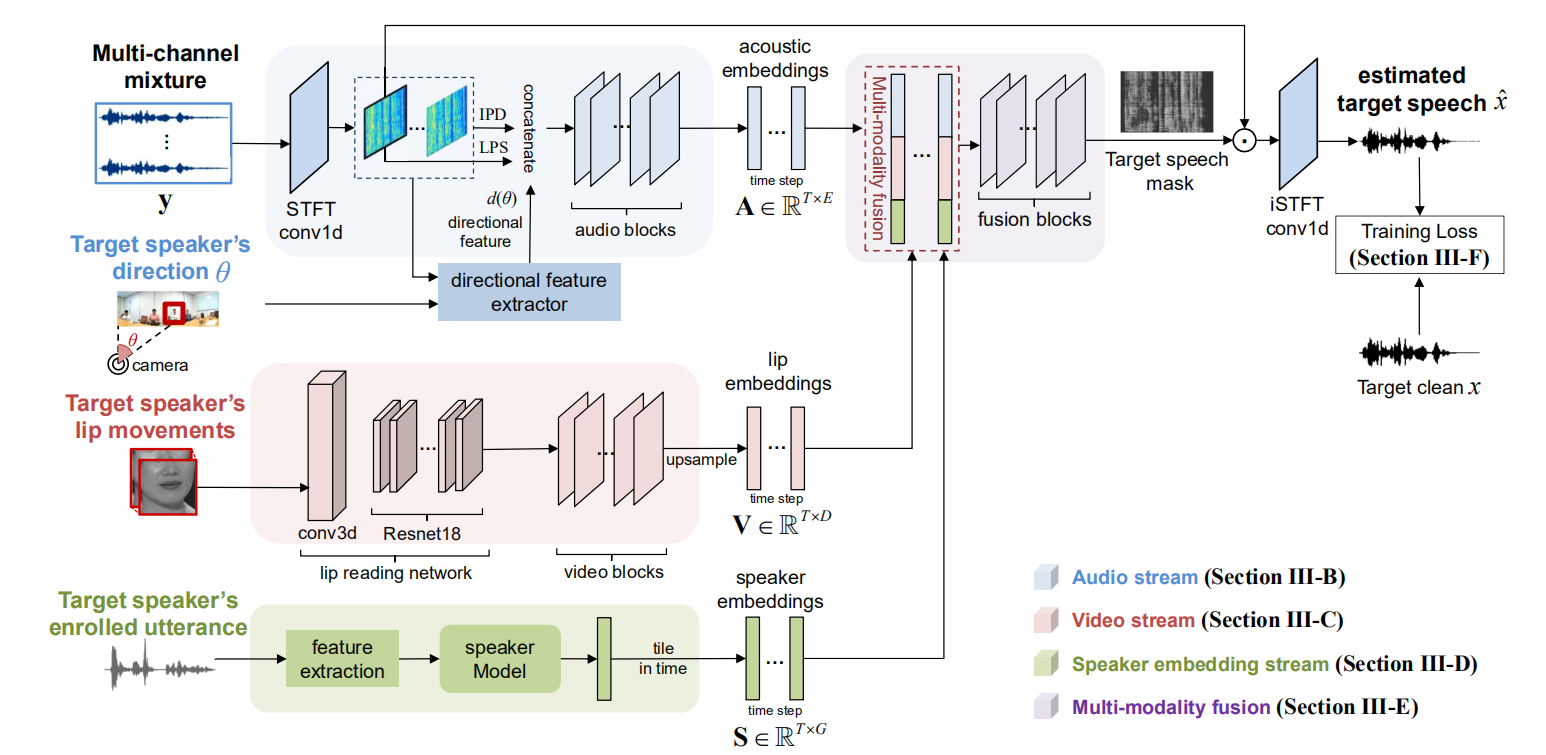
上图:所提出的多模态目标语音分离框架图
为了证明所提出的多模态语音分离深度模型的有效性和噪声鲁棒性,本论文开展了大量实验评测对模型的性能进行评估,包括视觉-听觉模态分别缺失、不同噪声条件。所采用的大规模音视频数据库从Youtube视频网站采集,并基于仿真的房间混响扩展成多通道。实验结果证明本论文所提出的多模态框架相对于单模态和双模态方法有显著的性能提升,且支持实时处理(RTF<1 )。
本文研究进一步表明,借鉴人类视听觉机制,在大数据驱动下的多模态语音分离深度模型展现出极强的竞争力,该研究成果为解决嘈杂环境下的语音识别和人机自然语音交互提供了新的技术途径。

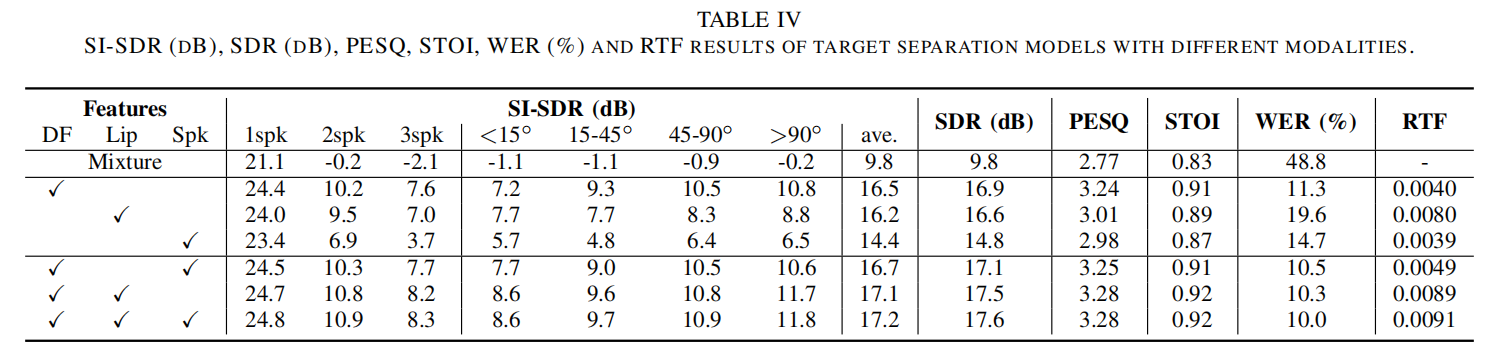
上表:在同框架下单模态、双模态和多模态语音分离系统性能比较
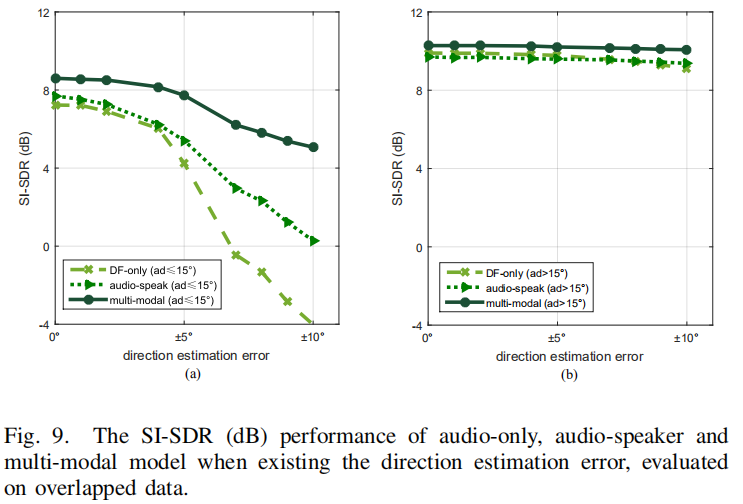
上图:单模态、双模态和多模态系统对目标语音方向估计误差的鲁棒性评测
JSTSP是中科院JCR期刊一区期刊,2019年的影响因子为6.688,是信号处理领域的顶级期刊之一。该论文是该期专刊的封面文章。课题组内顾容之博士为该论文第一作者,邹月娴教授为通讯作者。
供稿:十大网赌正规信誉网址邹月娴课题组